Instantly Generate SEO Optimized Articles
with AI
AI that understands your keywords and ranking goals.
Used by 40,000+ creators!
"Loving godlike mode man. Your tool is f**king amazing mate. It's ranking everywhere and for everything, e.g.my personal site, parasite seo, affiliate articles etc. And it's fast too!"

ALL PLANS HAVE ACCESS TO THESE FEATURES
Multiple Modes
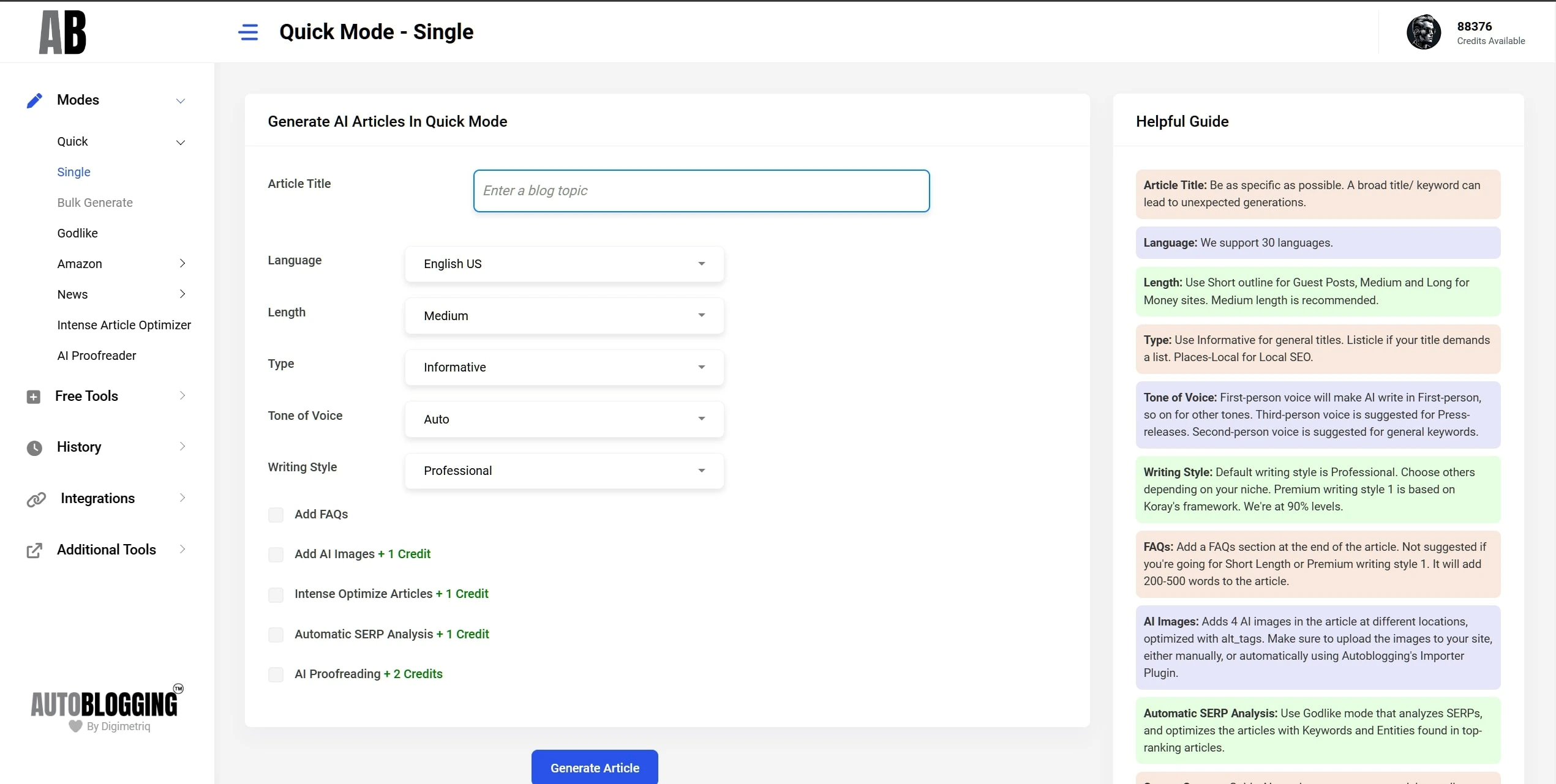
Quick Mode
Auto-pilot with Best Quality!
Generate High-quality SEO Optimised articles, hands-free and quickly!
Perfect for bloggers who want quality content without the hassle of configuration.
Feature Preview
Screenshot will appear here
Select a feature to explore
Quick Mode
Auto-pilot with Best Quality!
Generate High-quality SEO Optimised articles, hands-free and quickly!
Perfect for bloggers who want quality content without the hassle of configuration.
Feature Image
That's not it. There's so many new features
that we bring in every week!
TESTIMONIALS
What users say about Autoblogging:
Join 40,000+ content creators who trust us to scale their content
"This tool has always been up to date with the latest macro trends. Vaibhav's a nerd though. 🤓"

"I've always been a fan and enthusiast of AI and content, testing new tools and such during the GPT-3 Craze, and through that I've met Vaibhav. I've subscribed on all his models and tools as a beta tester and paid user and I gotta say, this current one is the best there is which understands both what the algorithm wants and what the user wants. I've gotten great success testing this new tool of his and making money out of it in a span of 3 weeks Definitely recommended guy, superb character of a person, gravity level genius, and really a good tool from him right now."

"Hey man, thank you for creating such a good app. The articles are coming out great as drafts and my editor easily turns them into solid articles."

"Autoblogging.ai is a godsend if you are running affiliate sites, content sites or local. Where most AI tools fail to produce quality content, Vaibhav's Autoblogging tool delivers articles that read like a human. This is next level AI where you can include your own NLP keywords for better SEO optimizations. On top of that, Vaibhav is a stand up guy who will work hard to support you with any issues or questions you might have. Top notch service!"

"Loving godlike mode man. Your tool is f**cking amazing mate. It's ranking everywhere and for everything, e.g.my personal site, parasite seo, affiliate articles etc. And it's fast too!"

"Autoblogging.ai stands out as a beacon of authenticity and expertise. Their commitment to delivering quality content has made them a trusted source in the blogging community."

"I have used the Autoblogging AI tool for my main website, my portfolio of websites, clients websites, and even parasite websites and the content generated ranked amazingly on all of them!"

"AI writing tools are only going to become more important for SEO and after testing all the artificial intelligence writers I found Autoblogging.ai to be the best AI writer. When I met Vaibhav (founder) I seen a keen, ambitious and motivated entrepreneur that could improve the tool and take it to the next level. I am very proud to be part of such an amazing AI writing tool and use Autoblogging.ai for many internal projects."

"Autoblogging.ai has revolutionized my content strategy. It provides a quality first draft for my articles at a fraction of the cost of other tools. Vaibhav, the founder, provides excellent client care."

"Autoblogging.ai has been a game-changer for SEOs worldwide. Its high-quality optimized content is generated quickly, streamlining our workflow. The multilingual support have expanded our boundaries significantly. The service saves us time, allowing us to focus on strategy and creativity. Overall, Autoblogging.ai has boosted our productivity and improved content quality. I highly recommend it to any marketing agency looking to elevate their content marketing efforts."

CHOOSE YOUR PLAN
Pricing
Start generating high-quality SEO articles today with our flexible pricing plans
Starter
✓ 40 credits/month
✓ Credits roll over
✓ Quick Mode (Single & Wizard)
✓ Godlike Mode & Amazon Reviews
✓ Intense Article Optimizer
✓ 1 WordPress site & 1 Email account
Regular
✓ 120 credits/month
✓ Credits roll over
✓ Everything in Starter, plus:
✓ News Mode
✓ AI Proofreader
✓ Semantic SEO Analysis
✓ 3 WordPress sites & 3 Email accounts
Standard
✓ 300 credits/month
✓ Credits roll over
✓ Everything in Regular, plus:
✓ Outreach Prospects
✓ Site Optimizer
✓ 5 WordPress sites & 5 Email accounts
Gold
✓ 600 credits/month
✓ Credits roll over
✓ Everything in Standard, plus:
✓ Topical Map
✓ 20 WordPress sites & 20 Email accounts
Premium
✓ 1000 credits/month
✓ Credits roll over
✓ Everything in Gold, plus:
✓ Unlimited WordPress sites
✓ Unlimited Email accounts
Enterprise
✓ 5000 credits/month
✓ Credits roll over
✓ Everything in Premium
✓ Priority support
Starter
✓ 40 credits/month
✓ Credits roll over
✓ All Starter features
Regular
✓ 120 credits/month
✓ Credits roll over
✓ All Regular features
Standard
✓ 300 credits/month
✓ Credits roll over
✓ All Standard features
Gold
✓ 600 credits/month
✓ Credits roll over
✓ All Gold features
Premium
✓ 1000 credits/month
✓ Credits roll over
✓ All Premium features
Enterprise
✓ 5000 credits/month
✓ Credits roll over
✓ All Enterprise features
✓ Priority support
What Can You Do With Your Credits?
| Mode/Feature | Credits/Article |
|---|---|
| Quick Mode (Single & Wizard) | 1 Credit |
| Godlike Mode | 2 Credits |
| Amazon Reviews Mode | 1 Credit |
| News Mode | 1 Credit |
| Intense Article Optimizer | 1 Credit |
| AI Proofreading | 1 Credit |
| Semantic SEO Analysis | 5 Credits |
| Outreach Prospects | 15 Credits |
| Topical Map Builder | 100 Credits |
Need more credits? Subscribers can top up additional credits anytime from their dashboard at special rates based on their plan tier.
DONE FOR YOU PACKAGES
Delegate to our VAs!
With our Done for you plans, we can handle the automations and upload content to your site, while you focus on the other aspects.
We understand that AI content has been improving a lot since the past 2 years and ranks on auto pilot as well. However, not all AI articles are perfect, and still requires human editing for faster growth, cleaner looks, and monetization approvals.
Choose Your DFY Package
Packages can be split with minimum 250 articles per site. A Google sheet will be maintained between us once you sign up.
Starter
For 1000 Articles
Bulk generation with Quick + Godlike Mode, Multiple AI Images, and auto-posting to WordPress.
+ Keyword Research & Topical Map: +$400
Pro
For 1000 Articles
Everything in Starter + Premium Writing Style + Automated Internal Linking between semantically related articles.
+ Keyword Research & Topical Map available
Corp
For 1000 Articles
Everything in Pro + Keyword Research + Human Editors + AI Proofreading + Infographics.
DFY with Human Editors
Senpai
For 1000 Articles
Everything in Corp + Custom editing guidelines + Personalized training for our editors.
Own Editing Guidelines
Ready to Scale Your Content?
Let our trained VAs handle your content generation while you focus on growing your business. Save hundreds of hours with our Done For You packages.
MEET THE EXPERTS
Our Team





Autoblogging.ai Interviews
Watch exclusive interviews with SEO experts and industry leaders sharing their insights and strategies
The Man Who Lost 3,000 Sites & Created "Topical Authority" — Koray Tugberk GUBUR
Learn from the SEO legend who pioneered the concept of topical authority and his journey through the industry.
He Was So Cheap Vietnam Outsourced to Him — Now He Has 270k Subscribers!
An incredible success story of building a massive YouTube following from humble beginnings.
SEE IT IN ACTION
Article Samples
Explore real examples of high-quality SEO articles generated across various niches and languages
Best AI Writing Tools for Content Creators in 2025
Best Smart Home Devices Worth Buying in 2025
Complete SEO Strategy for New Bloggers
Die Besten KI-Tools für Content Marketing in 2025
Best Investment Apps for UK Beginners
Guide Complet de la Cuisine Française Traditionnelle
EXPLORE OUR CONTENT
Learn & Stay Updated
Access our comprehensive resources and stay ahead with the latest updates
Latest AI News
Stay ahead with the latest updates in AI and SEO.
Auto-Updated Daily
Knowledge Base
Master SEO with in-depth explanations of key terms, strategies, and best practices from industry experts.
Video Tutorials
Watch step-by-step tutorials showing how to generate articles for different niches using Autoblogging.ai.
Learn More About Autoblogging.ai
How to use Source Context in Godlike Mode
Read more
Autoblogging.ai Now Supports 30 Languages (Samples Inside)
Read more
What's New in Autoblogging.ai?
Read more
What is Autoblogging?
In the digital age, content creation has evolved with the advent of AI technologies. One significant breakthrough in this domain is autoblogging, a method of generating blog content automatically. Autoblogging, also known as automatic blogging or automated blogging, leverages advanced software to create articles, eliminating the need for manual writing. This innovation has given rise to tools like autoblogging.ai, a leading name in the auto blogging software market.The Evolution of Auto Blogging Software
Originally, autoblogging was a simple process of aggregating content from different sources. However, with the integration of AI, autoblogging software like autoblogging.ai and autoblogger has become more sophisticated. These platforms use AI algorithms to generate unique and relevant content, transforming the concept of an auto blog writer into a reality.Autoblogging.ai Review
Among the various options, autoblogging.ai stands out. It has been praised for its efficient automatic blog writer capabilities. As an auto blogger, this platform offers a seamless experience in generating automatic blog posts, making it a favorite among users seeking an efficient auto ai writer. The autoblogging ai technology underpinning this platform ensures high-quality content generation.Features of Autoblogging Software
Key features of autoblogging software include automated blog writing, article generation, and scheduling of posts. Platforms like dash.buymorecredits.com and autoblogger nl offer these services, along with unique features like auto blog com and auto blogging wordpress integrations. The autoblogger plugin, particularly popular in the WordPress community, facilitates easy blog management.AI Blogging and Its Impact
AI blogging has revolutionized the way content is created. With ai auto write features, platforms like autoblogging samurai and wp auto blogger automate the entire content creation process. This includes automated article writing, a feature that allows for the generation of complete articles with minimal human input.Blogging with Artificial Intelligence
The core of AI blogging lies in ai blogging software, which powers the ai blogger. These tools are capable of understanding context and generating articles that are both relevant and engaging. AI auto writer technologies, including automatic writing website and blog ai writer features, are increasingly being adopted for their efficiency and time-saving benefits.The Rise of AI-Generated Blogs
The trend of ai generated blog and ai generated blogs is gaining momentum. Automatic ai writer tools are enabling even novice bloggers to produce content at an unprecedented scale. Automotive blogger platforms and other niche blogging sites are also adopting ai blog tools to enhance their content quality.Autoblogging Plugins and Tools
WordPress, being a popular blogging platform, offers a range of autoblogging plugin options like wordpress auto blogging. These plugins, such as autoblog wordpress, automate content generation, making it easier for bloggers to maintain a consistent posting schedule.Free AI Blogging Tools
The market also offers free blog writing ai tools. Platforms like ai blog post writer and wordpress autoblogging are making AI technology accessible to all bloggers. The ai automatic writing feature is particularly beneficial for those looking for a cost-effective solution.AI in Blog Writing
The integration of AI into blog writing has led to the development of ai writing blogs and ai for writing blog tools. These tools, including automatic writing ai and blog writer free options, are enhancing the blogging experience. Blog writing ai free tools are particularly popular among bloggers on a budget.The Future of AI Blogging
Looking ahead, the ai blog posts and automatic article writer technology will continue to evolve. The best ai blog writer tools will likely incorporate more advanced AI capabilities, making auto article writer and blog writer software even more sophisticated. Autoblogging.ai and similar platforms represent a significant advancement in content creation. The combination of ai writing blog and free blog writer ai tools is making blogging more accessible and efficient. As ai for blog posts technology continues to evolve, we can expect to see even more innovative solutions in the field of auto blogs and blog writing tool. The era of best ai blogs and ai bloggers is just beginning, and the potential for growth in this field is immense.Autoblogging.ai is a product of Digimetriq.com, the team behind innovative automation solutions for blogging. Our mission is to help bloggers, website owners and agencies save time and improve their online presence through cutting-edge technology.